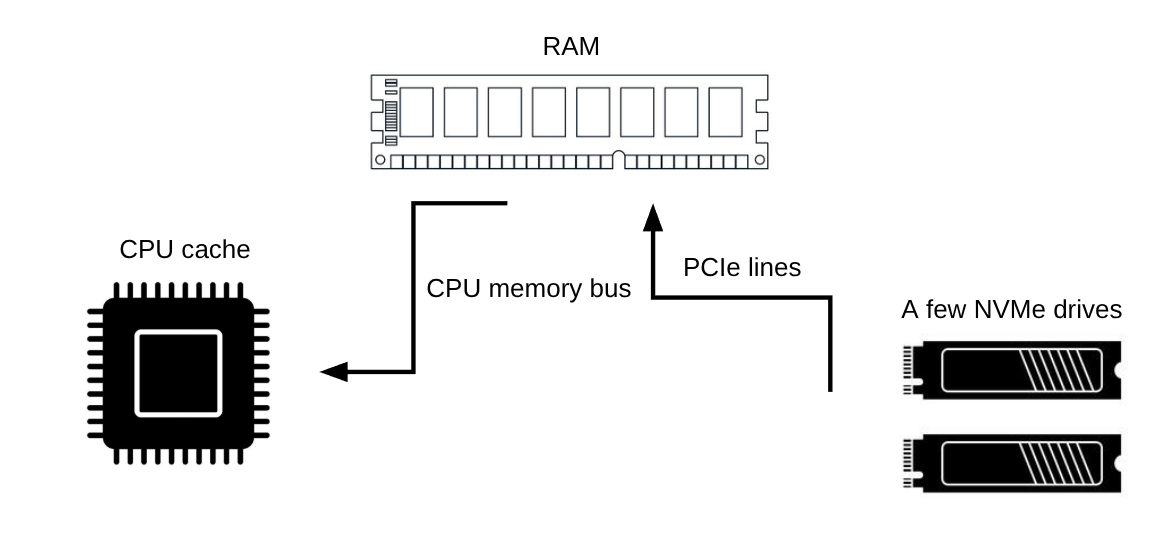
The project investigates the feasibility of implementing RAID (Redundant Array of Independent Disks) functionality using GPU acceleration through OpenCL. Traditional RAID systems rely on CPU-based calculations for data striping, mirroring, and parity computations, which can become a bottleneck in high-performance storage systems. The initial focus is on establishing a stable OpenCL development environment and benchmarking basic parallel operations to understand the potential benefits and limitations of GPU-accelerated RAID, including memory constraints, data transfer overhead, and overall system performance compared to conventional CPU-based implementations.
Report
The project has successfully established a working OpenCL environment on AMD GPU hardware and completed initial performance benchmarking. While computational kernels show promising performance improvements, overall system integration requires optimization to achieve net performance gains.
Key Results
- OpenCL Environment Stabilized: Resolved critical GPU driver crashes by identifying Mesa driver incompatibility ( version 24.3.0-devel) and downgrading to stable version 23.2.1-1ubuntu3.1.22.04.3
- Memory Capacity Verified: Successfully processed vector operations on arrays up to 26 million elements by optimizing system VRAM usage through TTY mode execution
- Performance Benchmarks Established: Achieved 21% faster execution for vector addition operations on GPU (0.11s) compared to CPU (0.14s), demonstrating computational advantage
- Integration Challenges Identified: Total program execution time currently exceeds CPU-only implementation due to overhead factors requiring further investigation
The immediate focus is on profiling overhead sources and optimizing data transfer patterns between CPU and GPU memory to achieve positive end-to-end performance gains before implementing specific RAID algorithms. Sources are available in GitHub repository.